DeepDive Applications
Here are a list of notable public DeepDive applications.
- MEMEX / Human trafficking
- TAC-KBP Challenge
- Wisci(-pedia)
- Geology and Paleontology
- Medical Genetics
- Pharmacogenomics
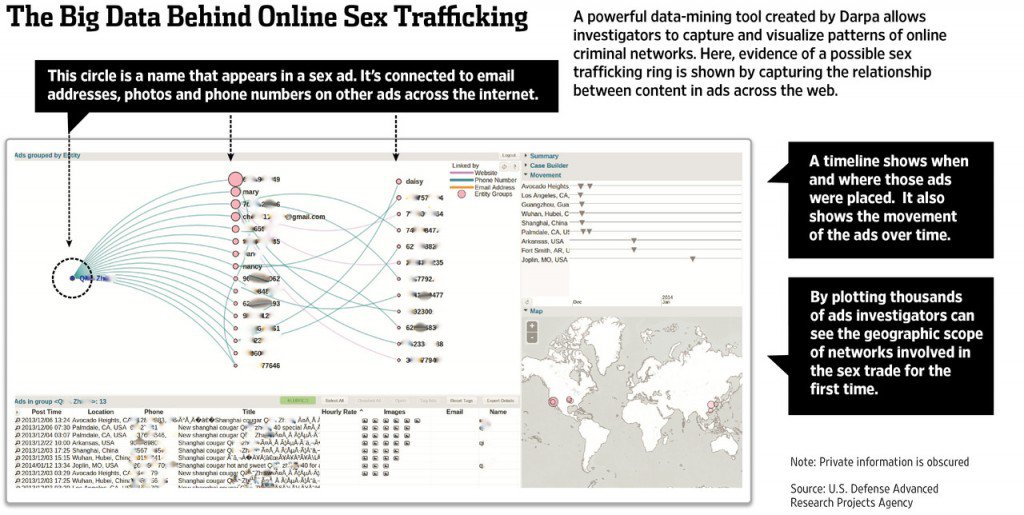
MEMEX / Human trafficking
MEMEX is a DARPA program that explores how next generation search and extraction systems can help with real-world use cases. The initial application is the fight against human trafficking. In this application, the input is a portion of the public and dark web in which human traffickers are likely to (surreptitiously) post supply and demand information about illegal labor, sex workers, and more. DeepDive processes such documents to extract evidential data, such as names, addresses, phone numbers, job types, job requirements, information about rates of service, etc. Some of these data items are difficult for trained human annotators to accurately extract and have never been previously available, but DeepDive-based systems have high accuracy (Precision and Recall in the 90s, which may exceed non-experts). Together with provenance information, such structured, evidential data are then passed on to both other collaborators on the MEMEX program as well as law enforcement for analysis and consumption in operational applications. MEMEX has been featured extensively in the media and is supporting actual investigations. For example, every human trafficking investigation pursued by the Human Trafficking Response Unity in New York City involves MEMEX. DeepDive is the main extracted data provider for MEMEX. See also, 60 minutes, Scientific American, Wall St. Journal, BBC, and Wired. It is supporting actual investigations and perhaps new usecases in the war on terror.
Here is a detailed description of DeepDive's role in MEMEX.
TAC-KBP Challenge
TAC-KBP (Text Analysis Conference, Knowledge Base Population track, organized by NIST) is a research competition where the task is to extract common properties of people and organizations (e.g., age, birthplace, spouses, and shareholders) from a few million of newswire and web documents -- this task is also termed Slot Filling. In the 2014 evaluation, 31 US and international teams participated in the competition, including a solution based on DeepDive from Stanford. The DeepDive based solution achieved the highest precision, recall, and F1 among all submissions. (See Table 6 in Mihai Surdeanu and Heng Ji. Overview of the English Slot Filling Track at the TAC2014 Knowledge Base Population Evaluation. Proceedings of the TAC-KBP 2014 Workshop, 2014.)
Wisci(-pedia)
Wisci is a first incarnation of the “encyclopedia built by the machines, for the people” vision. (It was developed by the Hazy research group when the team was at University of Wisconsin-Madison. Hence the project name.) We applied similar techniques as our solution to the TAC-KBP challenge -- namely NLP, distant supervision, and probabilistic inference -- over the ClueWeb09 corpus that contains 500 million web pages. The extraction and inference results include millions of common properties of people and organizations, as well as confidence scores and provenance. They are used to augment a Wikipedia mirror, where we supplement human-authored page content and infoboxes with related facts, references, excerpts, and videos discovered by DeepDive. Wisci also accepts user feedback and learns from it.

Geology and Paleontology
Geology studies history of the solid Earth; paleontology studies fossils and ancient organisms. At the core of both disciplines are discovery and knowledge sharing. In particular, the research communities have maintained two live databases: Macrostrat, which contains tens of thousands of rock units and their attributes, and the Paleobiology Database (PBDB), which contains hundreds of thousands of taxonomic names and their attributes. However, both projects require researchers to laboriously sift through massive amounts of scientific publications, find relevant statements, and manually enter them into the database. For example, PBDB has taken approximately nine continuous person years to read from roughly 40K documents in the past two decades. In collaboration with Prof. Shanan Peters at UW-Madison, we developed two DeepDive programs, GeoDeepDive and PaleoDeepDive, that process roughly 300K scientific documents (including text, tables, and figures). On the document set covered by both DeepDive and PBDB contributors (12K), DeepDive achieves recall roughly 2.5X that of humans, and precision that is as high as or higher than humans.

Medical Genetics
The body of literature in life sciences has been growing at accelerating speeds to the extent that it has been unrealistic for scientists to perform research solely based on reading and memorization (even with the help of keyword search). As a result, there have been numerous initiatives to build structured knowledge bases from literature. For example, OMIM is an authoritative database of human genes and genetic disorders. It dates back to the 1960s, and so far contains about 6,000 hereditary diseases or phenotypes. Because OMIM is curated by humans, it has been growing at a rate of roughly 50 records / month for many years. In collaboration with Prof. Gill Bejerano at Stanford, we are developing DeepDive applications in the field of medical genetics. Specifically, we use DeepDive to extract mentions of genes, diseases, and phenotypes from the literature, and statistically infer their relationships.
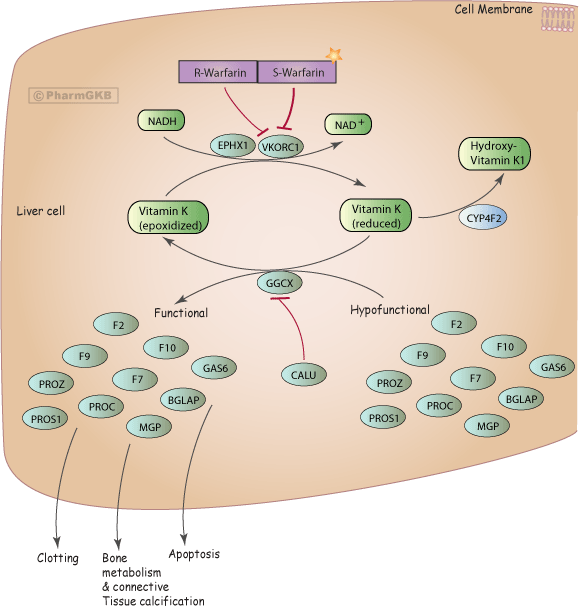
Pharmacogenomics
Understanding the interactions of small chemicals or drugs in the body is key for drug discovery. However, the majority of this data resides in the biomedical literature and cannot be easily accessed. The Pharmacogenomics Knowledgebase (PharmGKB, www.pharmgkb.org) is a high quality database that aims to annotate the relationships between drugs, genes, diseases, genetic variation, and pathways in the literature. With the exponential growth of the literature, manual curation requires prioritization of specific drugs or genes in order to stay up to date with current research. In collaboration with Emily Mallory (PhD candidate in the Biomedical Informatics training program) and Prof. Russ Altman at Stanford, we are developing DeepDive applications in the field of pharmacogenomics. Specifically, we use DeepDive to extract relations between genes, diseases, and drugs in order to predict novel pharmacological relationships.