
Knowledge base construction
Knowledge base construction (KBC) is the process of populating a knowledge base (KB) with facts (or assertions) extracted from data (e.g., text, audio, video, tables, diagrams, ...). For example, one may want to build a medical knowledge base of interactions between drugs and diseases, a Paleobiology knowledge base to understand when and where did dinosaurs live, or a knowledge base of people's relationships such as spouse, parents or sibling. DeepDive can be used to facilitate KBC.
As a concrete example, one may use DeepDive to build an application to extract
spouse relations from sentences in the Web. Figure 1 below shows such an
application, where the input consists of sentences like "U.S President Barack
Obama's wife Michelle Obama ...", and DeepDive's output consists of tuples in an
has_spouse table representing the fact that, for example, "Barack Obama" is
married to "Michelle Obama". DeepDive also produces a probability associated to
the fact, representing the system's confidence that the fact is true (refer to
the 'Probabilistic inference' document for more details
about this concept).
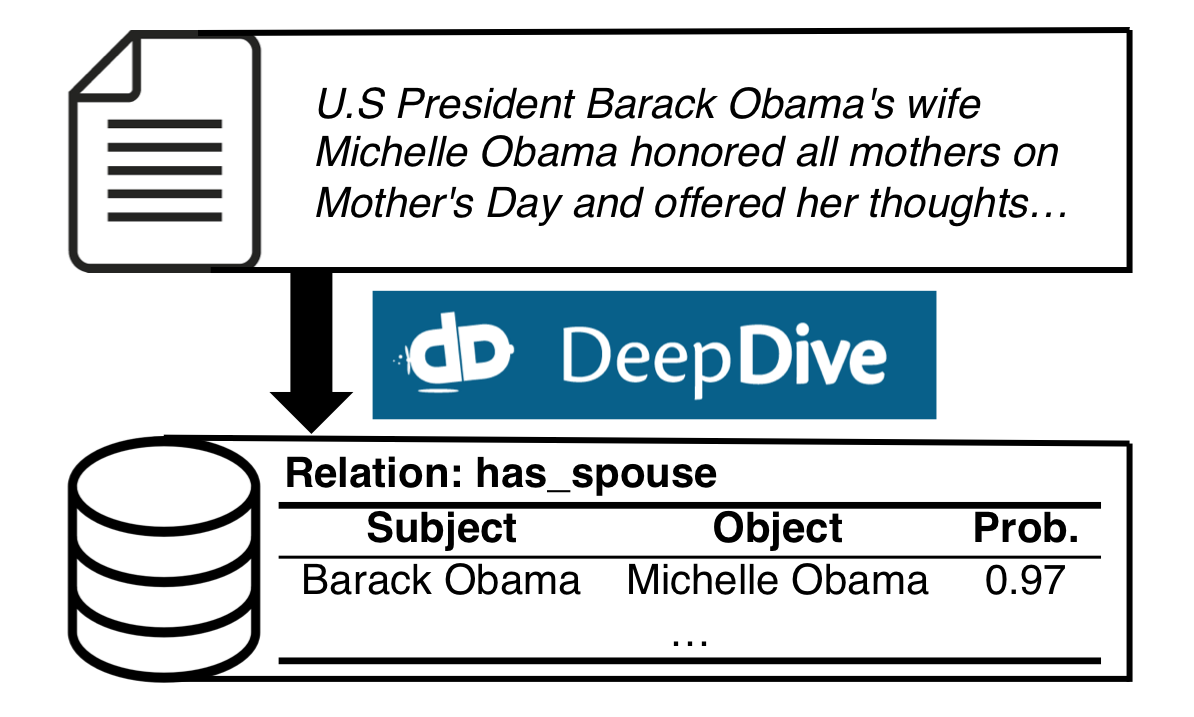
Figure 1: An example KBC application
KBC terminology
KBC uses specific terms to refer to the objects it manipulates. The following is a list of the most important ones
An entity is an object in the real world, such as a person, an animal, a time period, a location, etc. For example, the person "Barack Obama" is an entity.
Entity-level data are relational data over the domain of conceptual entities (as opposed to language-dependent mentions), such as relations in a knowledge base, e.g. "Barack Obama" in Freebase.
A mention is a reference to an entity, such as the word "Barack" in the sentence "Barack and Michelle are married".
Mention-level data are textual data with mentions of entities, such as sentences in web articles, e.g. sentences in New York Times articles.
Entity linking is the process to find out which entity is a mention referring to. For example, "Barack", "Obama" or "the president" may refer to the same entity "Barack Obama", and entity linking is the process to figure this out.
A mention-level relation is a relation among mentions rather than entities. For example, in a sentence "Barack and Michelle are married", the two mentions "Barack" and "Michelle" has a mention-level relation of
has_spouse.An entity-level relation is a relation among entities. For example, the entity "Barack Obama" and "Michelle Obama" has an entity-level relation of
has_spouse.
The relationships between these concepts (also known as the data model) is represented in Figure 2 below.
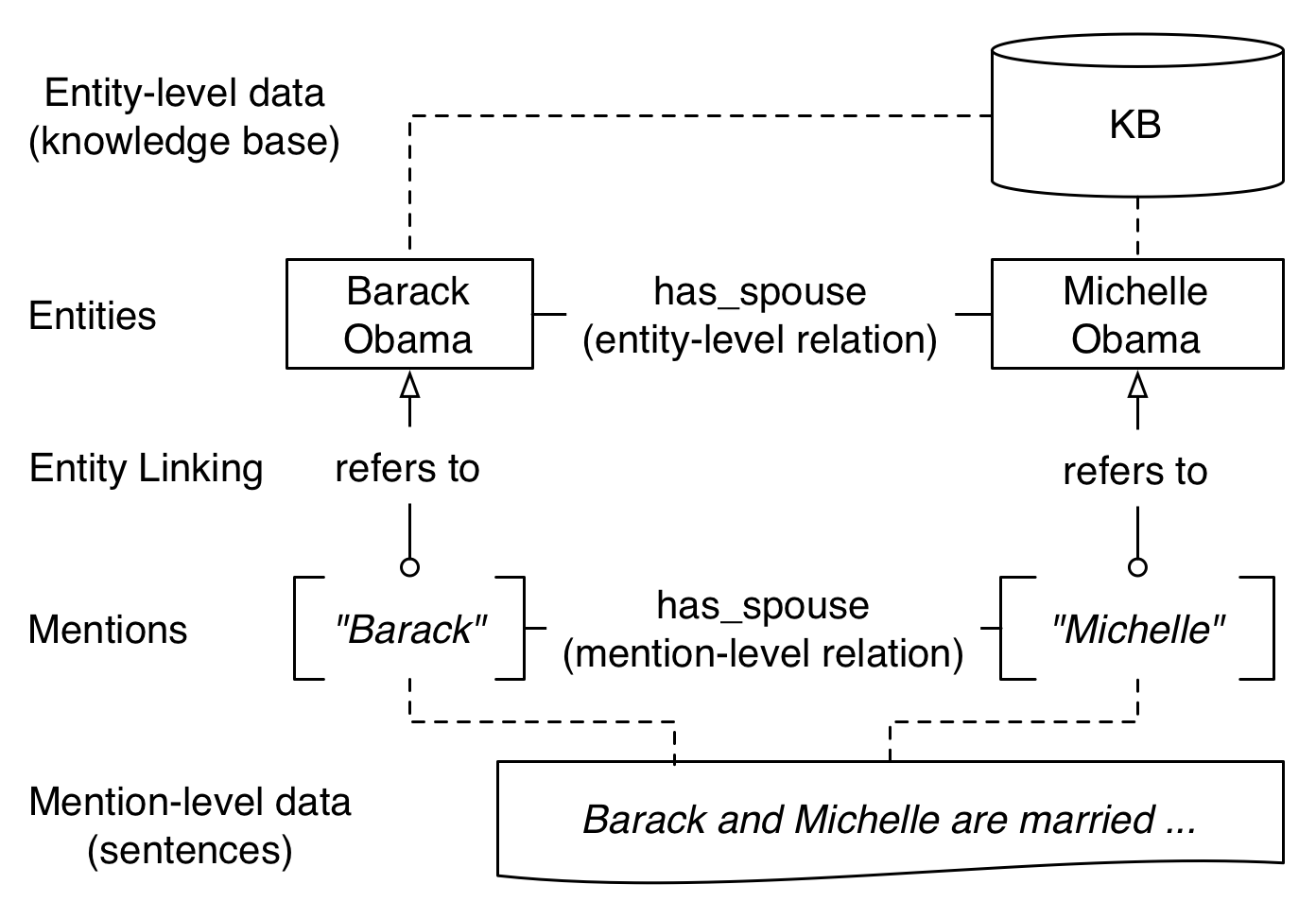
Figure 2: Data model for KBC
KBC data flow
In an typical KBC application, the input of the system is a collection of raw articles in text format, while the output of the system is a database (the KB) containing the desired (entity-level or mention-level) relations.
As explained in the System overview, the steps to obtained the output are the following:
- data preprocessing
- feature extraction
- factor graph generation by declarative language
- statistical inference and learning
Specifically:
In the data preprocessing step, DeepDive takes input data (articles in text format), loads them into a database, and parse the articles to obtain sentence-level information including words in each sentence, POS tags, named entity tags, etc.
In the feature extraction step, DeepDive converts input data into relation signals called evidence, by running extractors written by developers. Evidence includes: (1) candidates for (mention-level or entity-level) relations; (2) (linguistic) features for these candidates.
In the next step, DeepDive uses evidence to generate a factor graph. To instruct DeepDive about how to generate this factor graph, developers use a SQL-like declarative language to specify inference rules.
In the next step, DeepDive automatically performs learning and statistical inference on the generated factor graph. learning, the values of factor weights specified in inference rules are calculated. These weights represent, intuitively, the confidence in the rule. During the inference step, the marginal probabilities of the variables are computed, which, in some cases, can represent the probability that a specific fact is true.
After inference, the results are stored in a set of database tables. The developer can get results via a SQL query, check results with a calibration plot, and perform error analysis to improve results.
As an example of this data flow, Figure 3 demonstrates how a sentence "U.S President Barack Obama's wife Michelle Obama..." go through the process (In this figure, we only highlight step 1--3):
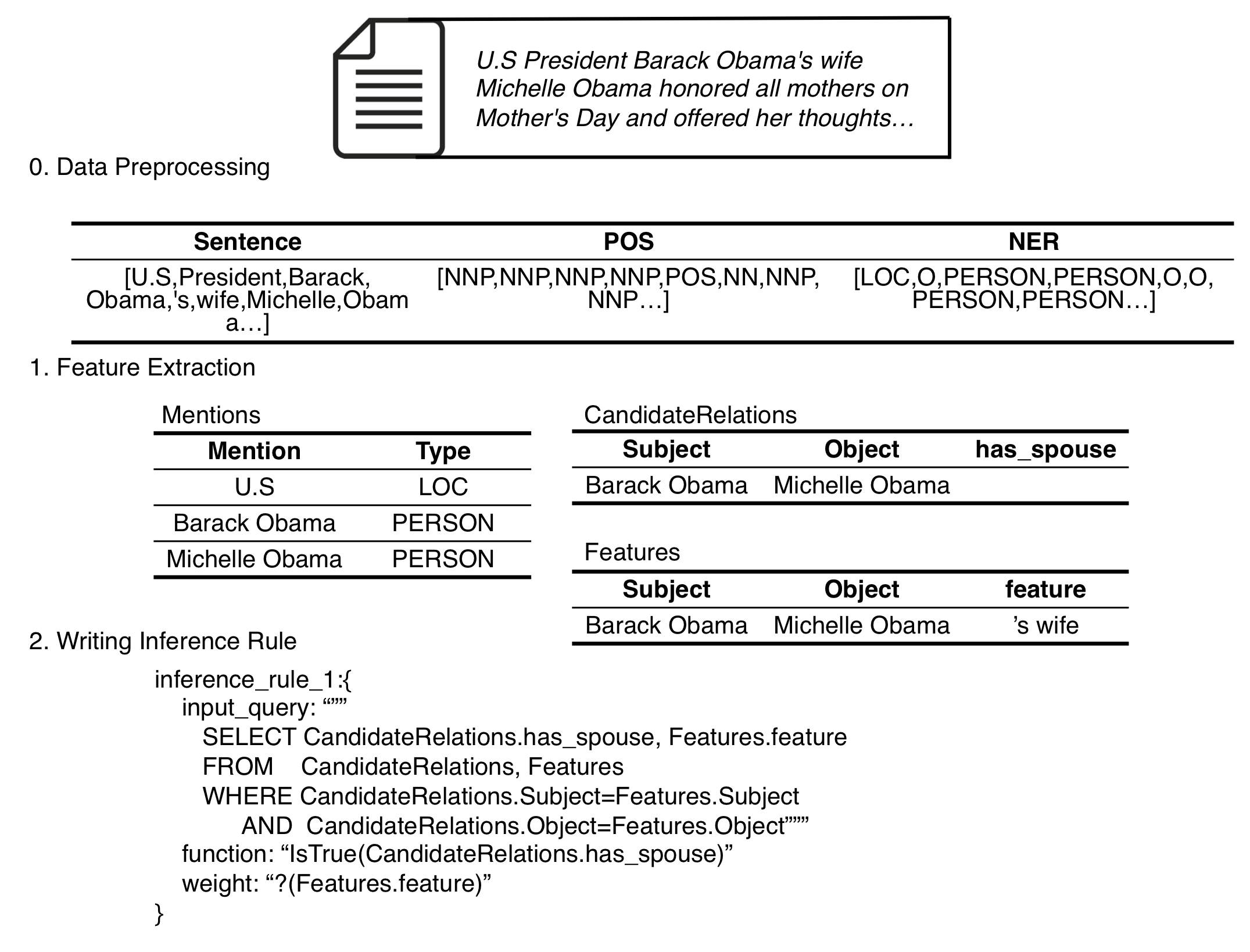
Figure 3: Data flow for KBC
In the example above:
During data preprocessing, the sentence is processed into words, POS tags and named entity tags;
During feature extraction, DeepDive extracts (1) mentions of person and location, (2) candidate relations of
has_spouse, and (3)featureof candidate relations (such as words between mentions).In factor graph generation, DeepDive use rules written by developers (like
inference_rule_1above) to build a factor graph.